3 Best Practices: Data and Metadata
3.1 Learning Objectives
In this lesson, you will learn:
- Why preserving computational workflows is important
- How to acheive practical reproducibility
- What are some best practices for data and metadata management
Download slides: Best Practices: Data and Metadata
3.2 Preserving computational workflows
Preservation enables:
- Understanding
- Evaluation
- Reuse
All for Future You! And your collaborators and colleagues across disciplines.

Figure 3.1: Scientific products that need to be preserved from computational workflows include data, software, metadata, and other products like graphs and figures.
While the Arctic Data Center and similar repositories do focus on preserving data, we really set our sights much more broadly on preserving entire computational workflows that are instrumental to advances in science. A computational workflow represents the sequence of computational tasks that are performed from raw data acquisition through data quality control, integration, analysis, modeling, and visualization.

Figure 3.2: Computational steps can be organized as a workflow streaming raw data through to derived products.
In addition, these workflows are often not executed all at once, but rather are divided into multiple workflows, earch with its own purpose. For example, a data acquistion and cleaning workflow often creates a derived and integrated data product that is then picked up and used by multiple downstream analytical workflows that produce specific scientific findings. These workflows can each be archived as distinct data packages, with the output of the first workflow becoming the input of the second and subsequent workflows.
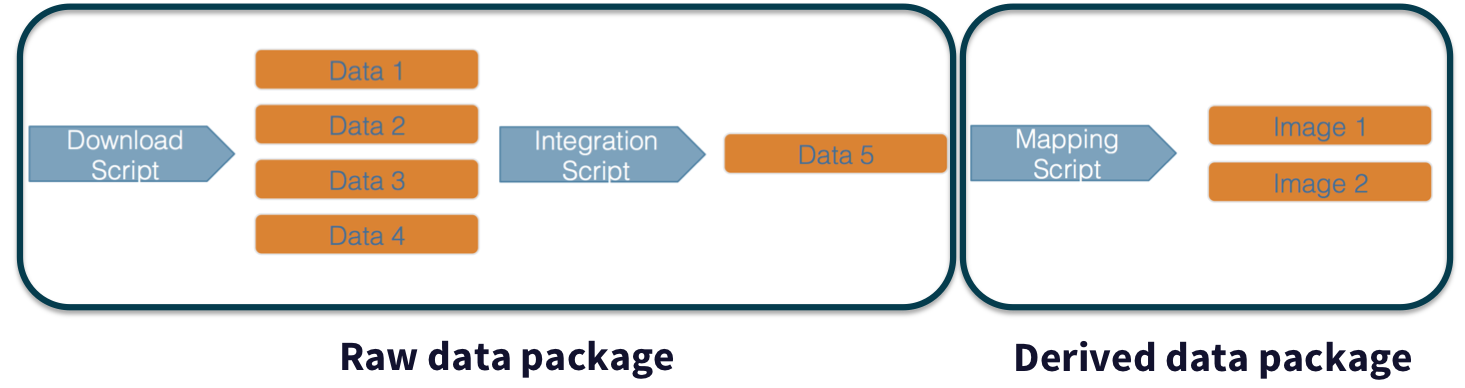
Figure 3.3: Computational workflows can be archived and preserved in multiple dat apackages that are linked by their shared components, in this case an intermediate data file.
3.3 Best Practices: Overview
- Who Must Submit?
- Organizing Data
- File Formats
- Large Data Packages
- Metadata
- Data Identifiers
- Provenance
- Licensing and Distribution

3.4 Organizing Data: Best Practices
Both (Borer et al. (2009)) and (White et al. (2013)) provide some practical guidelines for organizing and structuring data. Critical aspects of their recommendations include:
- Write scripts for all data manipulation
- Uncorrected raw data file
- Document processing in scripts
- Design to add rows, not columns
- Each column one variable
- Each row one observation
- Use nonproprietary file formats
- Descriptive names, no spaces
- Header line
References
Borer, Elizabeth, Eric Seabloom, Matthew B. Jones, and Mark Schildhauer. 2009. “Some Simple Guidelines for Effective Data Management.” Bulletin of the Ecological Society of America 90: 205–14. https://doi.org/10.1890/0012-9623-90.2.205.
White, Ethan, Elita Baldridge, Zachary Brym, Kenneth Locey, Daniel McGlinn, and Sarah Supp. 2013. “Nine Simple Ways to Make It Easier to (Re)use Your Data.” Ideas in Ecology and Evolution 6 (2). https://doi.org/10.4033/iee.2013.6b.6.f.